class Array(object): """ Achieve an Array by Python list """ def __init__(self, size = 32): self._size = size self._items = [None] * size
def __getitem__(self, index): """ Get items :param index: get a value by index :return: value """ return self._items[index]
def __setitem__(self, index, value): """ set item :param index: giving a index you want to teset :param value: the value you want to set :return: """ self._items[index] = value
def __len__(self): """ :return: the length of array """ return self._size
def clear(self, value=None): """ clear the Array :param value: set all value to None :return: None """ for i in range(self._size): self._items[i] = value
def __iter__(self): for item in self._items: yield item class MaxHeap(object): def __init__(self, maxsize=None): self.maxsize = maxsize self._elements = Array(maxsize) self._count = 0
def __len__(self): return self._count
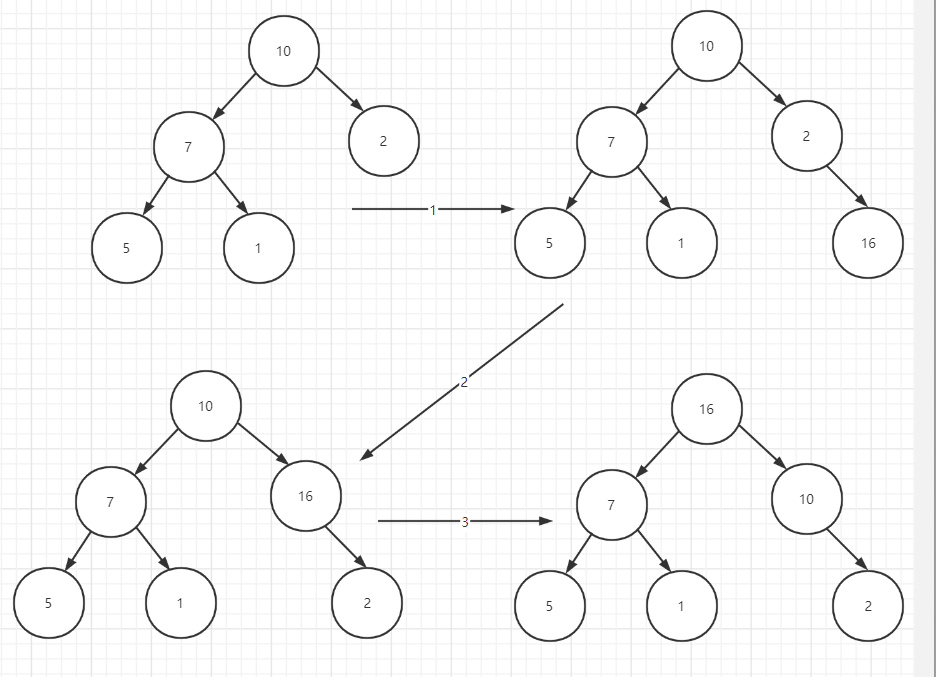
def add(self, value): if self._count >= self.maxsize: raise Exception('full') self._elements[self._count] = value self._count += 1 self._siftup(self._count-1) # 维持堆的特性
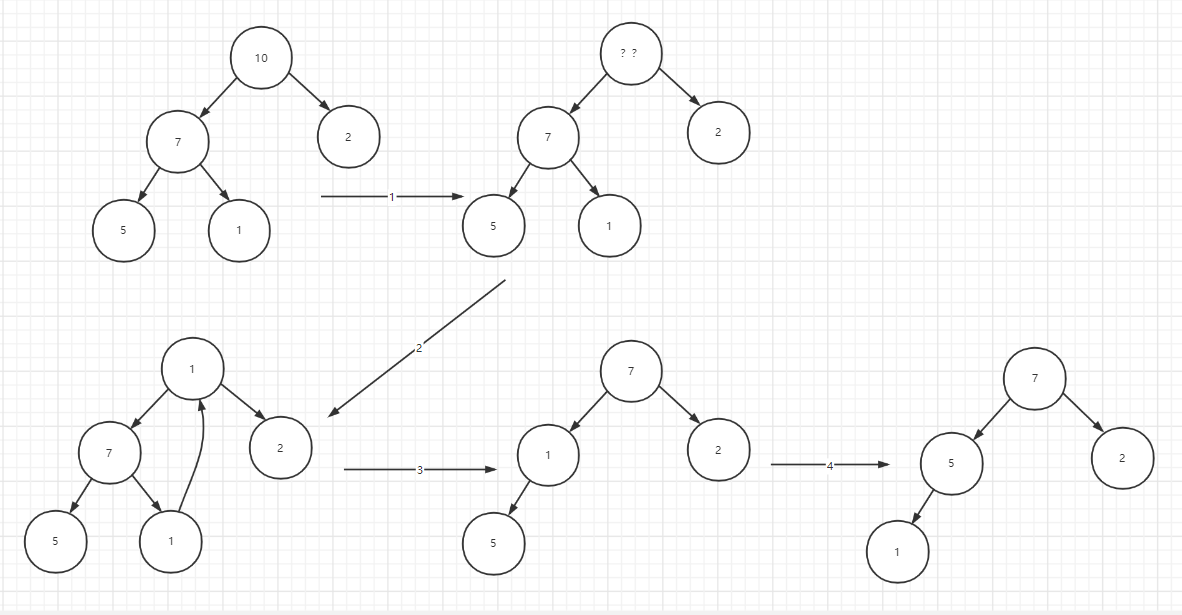
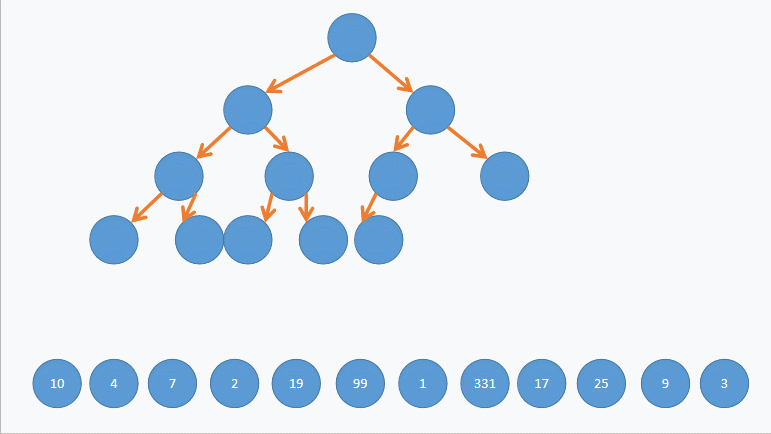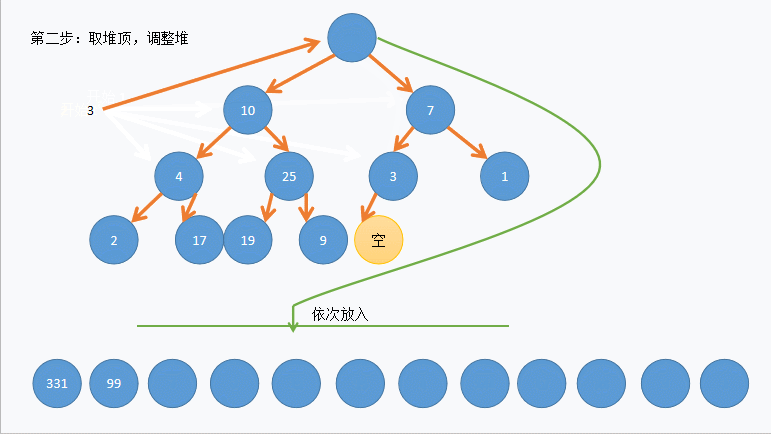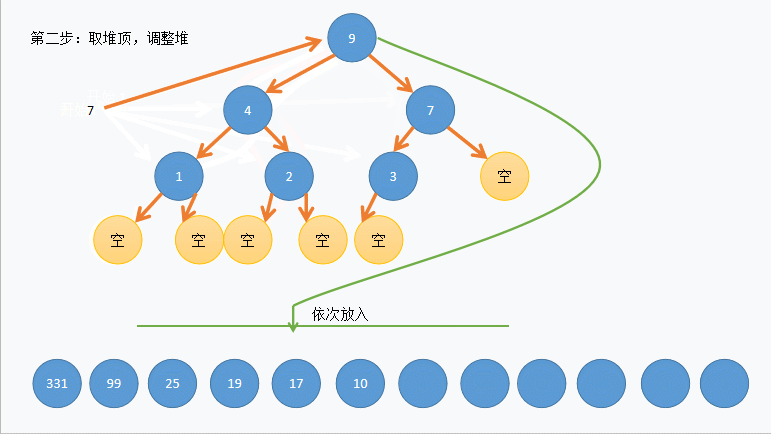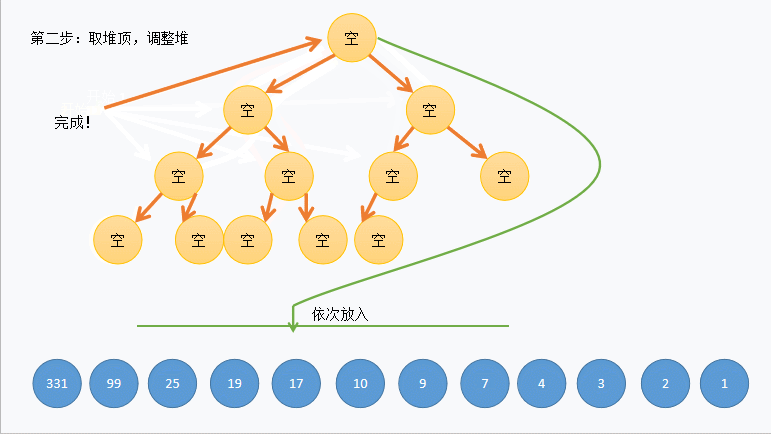
def extract(self): if self._count <= 0: raise Exception('empty') value = self._elements[0] # 保存 root 值 self._count -= 1 self._elements[0] = self._elements[self._count] # 最右下的节点放到root后siftDown self._siftdown(0) # 维持堆特性 return value
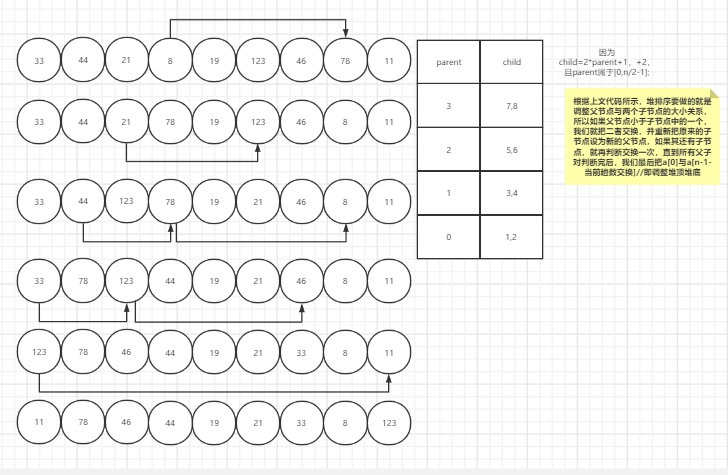
def _siftdown(self, ndx): left = 2 * ndx + 1 right = 2 * ndx + 2 # determine which node contains the larger value largest = ndx if (left < self._count and # 有左孩子 self._elements[left] >= self._elements[largest] and self._elements[left] >= self._elements[right]): # 原书这个地方没写实际上找的未必是largest largest = left elif right < self._count and self._elements[right] >= self._elements[largest]: largest = right if largest != ndx: self._elements[ndx], self._elements[largest] = self._elements[largest], self._elements[ndx] self._siftdown(largest)
def test_maxheap(): import random n = 5 h = MaxHeap(n) for i in range(n): h.add(i) for i in reversed(range(n)): assert i == h.extract()